Airtable
Airtable is a cloud-based platform that merges spreadsheet and database functionalities for easy data management and collaboration.
This Airtable dlt verified source and
pipeline example
loads data using “Airtable API” to the destination of your choice.
Sources and resources that can be loaded using this verified source are:
| Name | Description |
|---|---|
| airtable_source | Retrieves tables from an Airtable base |
| airtable_resource | Retrives data from a single Airtable table |
Setup Guide
Grab Airtable personal access tokens
- Click your account icon top-right.
- Choose "Developer Hub" from the dropdown.
- Select "Personal access token" on the left, then "Create new token".
- Name it appropriately.
- Add read scopes for "data records" and "schema bases".
- Add a base to specify the desired base for data access.
- Hit "Create token" and save the displayed token securely for credential use.
Note: The Airtable UI, which is described here, might change. The full guide is available at this link.
Grab Airtable IDs
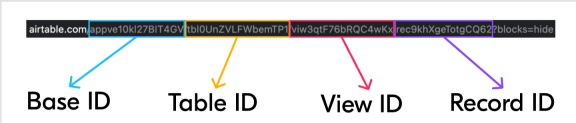
Upon logging into Airtable and accessing your base or table, you'll notice a URL in your browser's address bar resembling:
https://airtable.com/appve10kl227BIT4GV/tblOUnZVLFWbemTP1/viw3qtF76bRQC3wKx/rec9khXgeTotgCQ62?blocks=hide
Between each slash, you'll find identifiers for the base, table, and view as explained in this documentation on finding Airtable IDs:
Base IDs start with "app", currently set to "appve10kl227BIT4GV".
Table IDs start with "tbl", currently set to "tblOUnZVLFWbemTP1".
View IDs start with "viw", currently set to "viw3qtF76bRQC3wKx".
Record IDs start with "rec", currently set to "rec9khXgeTotgCQ62".
Initialize the verified source
To get started with your data pipeline, follow these steps:
Enter the following command:
dlt init airtable duckdbThis command will initialize the pipeline example with Airtable as the source and duckdb as the destination.
If you'd like to use a different destination, simply replace
duckdbwith the name of your preferred destination.After running this command, a new directory will be created with the necessary files and configuration settings to get started.
For more information, read the guide on how to add a verified source..
Add credentials
In the
.dltfolder, there's a file calledsecrets.toml. It's where you store sensitive information securely, like access tokens. Keep this file safe.Use the following format for service account authentication:
[sources.airtable]
access_token = "Please set me up!" # please set me up!Finally, enter credentials for your chosen destination as per the docs.
Next you need to configure ".dlt/config.toml", which looks like:
[sources.airtable]
base_id = "Please set me up!" # The id of the base.
table_names = ["Table1","Table2"] # A list of table IDs or table names to load.Optionally, you can also input "base_id" and "table_names" in the script, as in the pipeline example.
For more information, read the General Usage: Credentials.
Run the pipeline
Before running the pipeline, ensure that you have installed all the necessary dependencies by running the command:
pip install -r requirements.txtYou're now ready to run the pipeline! To get started, run the following command:
python airtable_pipeline.pyOnce the pipeline has finished running, you can verify that everything loaded correctly by using the following command:
dlt pipeline <pipeline_name> showFor example, the
pipeline_namefor the above pipeline example isairtable, you may also use any custom name instead.
For more information, read the guide on how to run a pipeline.
Sources and resources
dlt works on the principle of sources and
resources.
Source airtable_source
This function retrieves tables from given Airtable base.
@dlt.source
def airtable_source(
base_id: str = dlt.config.value,
table_names: Optional[List[str]] = None,
access_token: str = dlt.secrets.value,
) -> Iterable[DltResource]:
...
base_id: The base's unique identifier.
table_names: A list of either table IDs or user-defined table names to load. If not specified, all
tables in the schema are loaded.
access_token: Your personal access token for authentication.
Resource airtable_resource
This function retrieves data from a single Airtable table.
def airtable_resource(
api: pyairtable.Api,
base_id: str,
table: Dict[str, Any],
) -> DltResource:
...
table: Airtable metadata, excluding actual records.
Customization
Create your own pipeline
If you wish to create your own pipelines, you can leverage source and resource methods from this verified source.
Configure the pipeline by specifying the pipeline name, destination, and dataset as follows:
pipeline = dlt.pipeline(
pipeline_name="airtable", # Use a custom name if desired
destination="duckdb", # Choose the appropriate destination (e.g., duckdb, redshift, post)
dataset_name="airtable_data" # Use a custom name if desired
)To load the entire base:
base_id = "Please set me up!" # The id of the base.
airtables = airtable_source(base_id=base_id)
load_info = pipeline.run(load_data, write_disposition="replace")To load selected tables from a base table:
base_id = "Please set me up!" # The id of the base.
table_names = ["Table1","Table2"] # A list of table IDs or table names to load.
airtables = airtable_source(
base_id = base_id,
table_names = table_names
)
load_info = pipeline.run(airtables, write_disposition = "replace")You have the option to use table names or table IDs in the code above, in place of "Table1" and "Table2".
To load data and apply hints to a specific column:
base_id = "Please set me up!" # The id of the base.
table_names = ["Table1","Table2"] # A list of table IDs or table names to load.
resource_name = "Please set me up!" # The table name we want to apply hints.
field_name = "Please set me up!" # The table field name for which we want to apply hints.
airtables = airtable_source(
base_id="Please set me up!",
table_names=["Table1","Table2"],
)
airtables.resources[resource_name].apply_hints(
primary_key=field_name,
columns={field_name: {"data_type": "text"}},
)
load_info = pipeline.run(airtables, write_disposition="replace")
print(load_info)
Additional Setup guides
- Load data from Airtable to ClickHouse in python with dlt
- Load data from Airtable to CockroachDB in python with dlt
- Load data from Airtable to MotherDuck in python with dlt
- Load data from Airtable to YugabyteDB in python with dlt
- Load data from Airtable to Redshift in python with dlt
- Load data from Airtable to Azure Cloud Storage in python with dlt
- Load data from Airtable to Azure Synapse in python with dlt
- Load data from Airtable to Microsoft SQL Server in python with dlt
- Load data from Airtable to DuckDB in python with dlt
- Load data from Airtable to AlloyDB in python with dlt